Data Warehouses are slightly different from my typical project past (I’m far more au fait with custom software or package configuration / implementation gigs).
However, there’s an interesting aspect of Data Warehouses that can make them very suitable for more experimental/research oriented delivery techniques. To set that sentence in some context, I see two main categories of advantage to having a Data Warehouse:
- Regular Reporting that’s more insulated from changes to operational systems that feed the reporting (this is an Efficiency type of advantage)
- By aggregating multiple data items, it is possible to increase the probability of discovering previously unexplored patterns and relationships (this is an Insight type of advantage)
It’s this second advantage (see something like https://www.youtube.com/watch?v=X30tpFcKlp8 ), if a little hard to quantify, that I’m interested in.
Running an Experiment
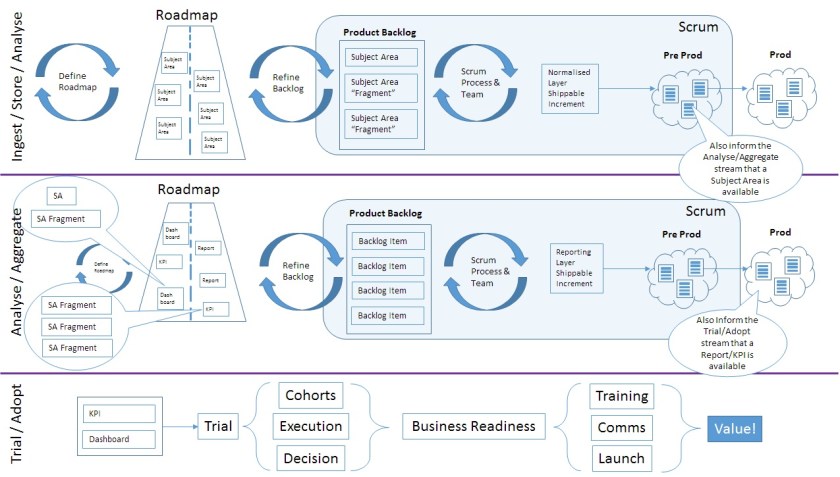
Assuming the data already exists somewhere in the Warehouse, the high level end to end flow is fairly straightforward

Delivering “The Tech”
The analysis and transformation work seeks to create information by transforming the underlying data into useful structures. It is sometimes impossible to predetermine exactly what structures would be useful, leading to the need for experimentation / trial-and-error or other uncertainty-reduction-strategies. The transformation efforts can be split into two parts (if necessary). Converting a source system data model into a logical (or canonical) model is a useful step, as it allows the Data Warehouse users to decouple themselves from the inner workings of a source system. This canonical form is typically in 3NF. Converting the canonical form into a Facts and Dimensions model is a useful step to improve the reportability characteristics of the data. However, this step can often only be performed once there is enough insight into the sorts of questions that the datasets need to answer.
The aggregation work seeks to combine potentially related sets of information to be able to reveal additional patterns and trends and create insight. This insight is where the value is when using a Data Warehouse (or more precisely, these insights can be acted upon to generate additional value for the business).
A continuous delivery model can work well in this context, particularly if there is a strong desire to create differentiation in a mature market. Work can usually be delivered quickly as in these scenarios there are usually no new architecturally significant requirements that need to be met (mainly because the Data Warehouse already exists, is operational, and has been sized to also cope with a reasonable degree of ad hoc reporting).
Mind the Gap
There are scenarios that don’t easily fall into that model. One significant one is when the raw data to be used does not yet exist in the Data Warehouse.
The solution to this problem is to introduce additional steps in the value stream, moving it left to also include ingesting the new data source as well as integrating (e.g. cleansing) the data and storing it in a coherent manner.

Filling the Gap
The Ingest & Store activities can be performed with a couple of different strategies.
- The first strategy is to only Ingest & Store what is required by the downstream work (i.e. the Analyse and Transform work identifies the specific data gaps. Those are filled)
- The second strategy is to Ingest and Store everything that is available from the data source, regardless of whether or not it is needed
The main benefit of the first strategy, is that only valuable work will be carried out (more just-in-time and less just-in-case). The main disadvantage is the time/effort it takes to build or change an Ingest process (this is typically an architecturally significant piece of work). An interesting side effect of only ingesting what is needed, is that it’s much slower to “just explore data and discover new insights”. In other words, serendipity is far less likely to work for you.
The main disadvantage of the second strategy, is that it can take more time (and money) than the first strategy to get to the version-one-dataset (i.e. the dataset known to be needed). The main advantage is that it is more likely that unforeseen relationships can be discovered, and those insights could be a source of a competitive advantage. However, there are no guarantees
The Client Specific Problem
There is a lot of advice and guidance that’s applicable to evolving “established” Data Warehouses. There is comparatively little advice and guidance on how to bootstrap your Data Warehouse and start generating value from it even when there’s extremely little data contained. A lot of the latter guidance uses tangible outputs (e.g. a report or a dashboard) as a way to bound the early work.
The initial ask of the project team (more accurately a platform team, but that’s a topic for another day) was to produce two reports for two business units. These two reports represented a significant piece of value. These were both fairly mature reports, having been developed and enhanced over a number of years. This was the strategy for being able to unlock value from the Data Warehouse at an early stage.
However, as the work progressed, it became apparent that there were significantly more data sources involved in the production of the complete reports (only discovered when new outputs were compared to the existing reports). In this environment, the work required to Ingest a new data source has significant architectural requirements to be satisfied before the data contained is accessible for use. The initial planning assumptions that led to the selection of these reports to be the first business use of the Data Warehouse were proven to be false. Seeing as all of the reports / dashboards that were deemed to be valuable were of similar ages (i.e. have been evolved and refined over a number of years) it was reasonable to assume that similar deal breakers would emerge unless far more thorough data analysis was performed.
A different strategy was needed. Instead of “trying to deliver a pre-defined thing”, what would happen if the focus shifted towards “get datasets into the Warehouse ASAP”? The ability to deliver a specific thing would suffer. However, the ability for the business to explore their data and attempt to derive meaning and insight from it would be improved. It involves a reframing of the ask. Moving from “Recreate X” towards “Try to make use of Y”. It gives the business users a chance to stretch their creativity muscles.
This proved to be a bridge too far. The rest of the “Change Organisation” had been optimised for projects. Or perhaps that should be “had evolved to make Projects the easiest vessel for money to effect changes”. Asking that organisation to switch to what is essentially a far more open ended “Research” mode of working wasn’t feasible in the short-medium (and I’m not holding out much hope for “long” right now) term.
So we found a halfway house. A Frankenstein-esque mesh of “push oriented work” and “value/pull driven work”. Development efficiency was the main driving force behind the sequencing of the Ingest/Store/Analyse elements. Datasets would be pushed onto the Data Warehouse in as efficient a manner as possible. Experimentation and “Product Development” was the main driving force behind the Analyse/Aggregate/Trial/Adopt elements. The most valuable reports and KPIs were targeted first, and experiments would be run to work out viable ways of delivering the insights using whatever datasets were available at that time. Interim solutions would be accepted, knowing that when additional datasets were delivered onto the Warehouse, it offered the chance for refactoring and redevelopment to occur.
It’s not pretty, but it’s a huge step forward from where the team was when I joined. Hopefully this one remains benevolent…