Subtitle: Are you optimising for development efficiency, bleeding edge innovation, production stability or credibility?
Context
I have a client that’s going through an agile transformation. They’re a core Infrastructure “horizontal” global (sub)organisation. In other words, they keep the lights on, look after all the Crown Jewels, and their customers tend to be application teams OR “everyone” (e.g. Exchange, DNS etc). They’ve adopted one of the many “spotify-variants” and are trying hard to make those structures work in their context.
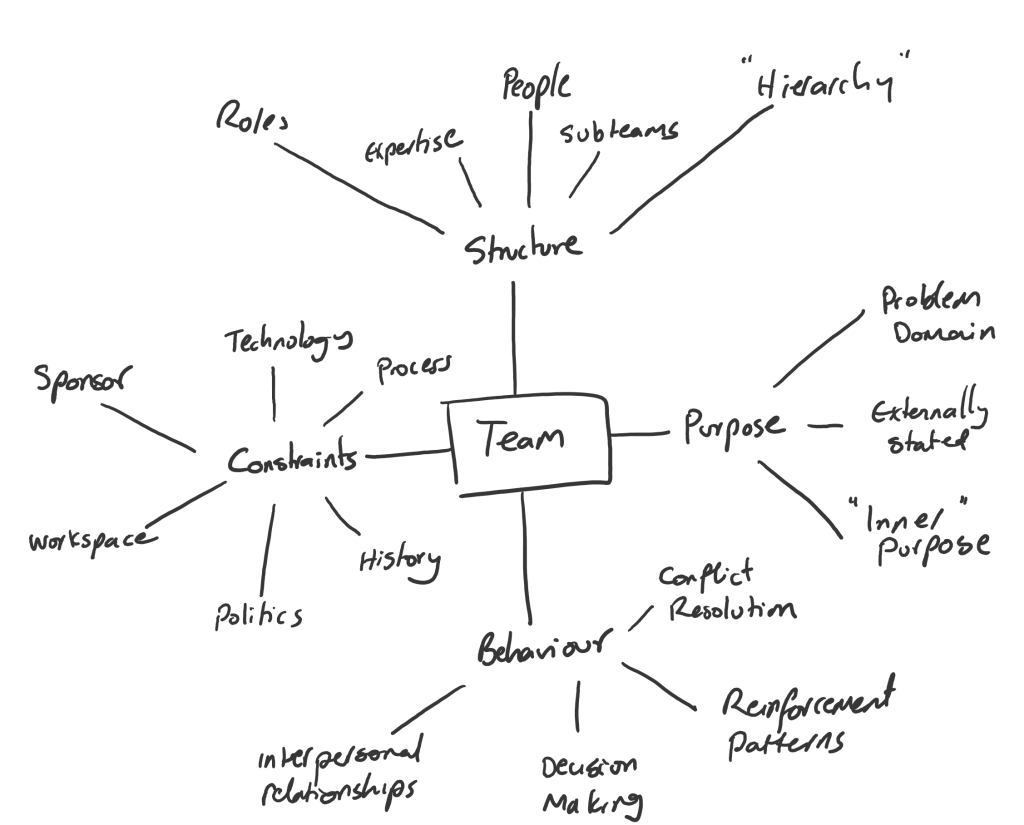
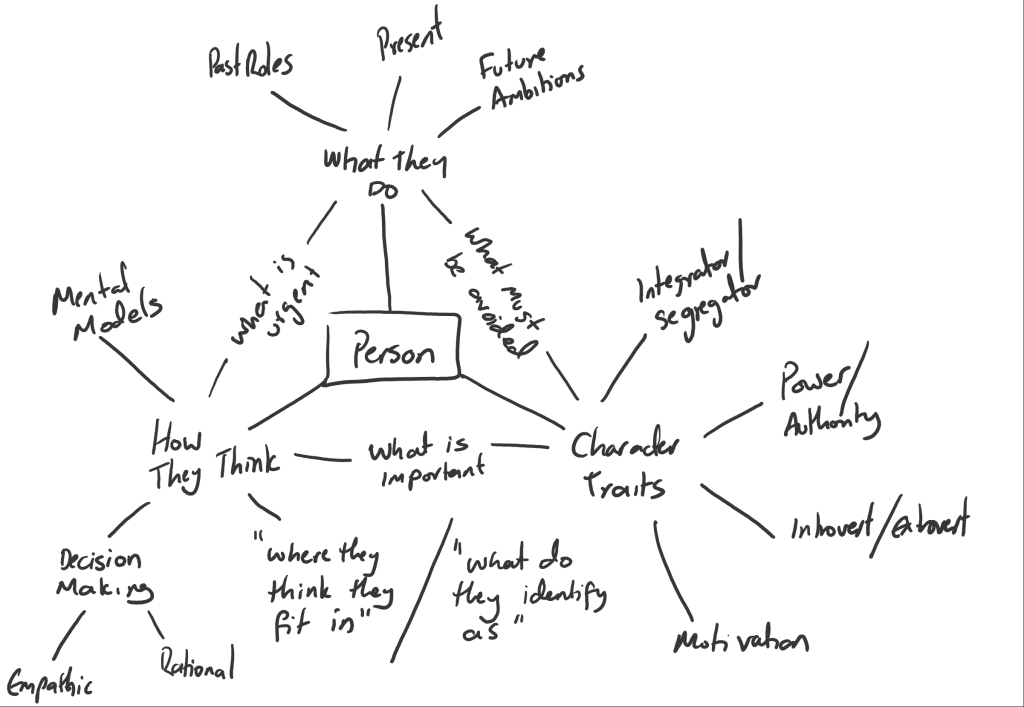
This post was triggered by a set of conversations I’ve been having with “platform leads” (higher end of middle management in the classic sense, they report directly to a C-suite senior leader). The topic was team design. More specifically, who should be appointed as the Product Owner for any given team. The first thing they needed to understand, was why the decision was architecturally significant (beyond the significance of the team that owns a service). Character traits and personal priorities in the product owner would shape the nature of the engagement a team has with their customers and stakeholders.
Before
There tended to be a couple of significant patterns.
Pattern 1: The most senior team member, sometimes a manager. These tended to be people who’ve been at this organisation the longest.
Pattern 2: The most technically skilled developer/technical architect/technical specialist. These tended to be people who know the most about what the product(s) or technologies are capable of.
The Problem
The main problem is the trade-offs aren’t explicitly visible. For example, sure it’d be great for technical quality and feature set richness if the forward thinking R&D person is put in charge, but there’s a significant risk to credibility when dealing with operational teams who have to service customer requests (if for example, the forward thinking person is uninterested in the “mundane day-to-day” and recommends waiting for a solution that isn’t live yet). For teams that are part of an ecosystem of teams that collectively deliver a live service, coordination and collaboration tend to be much more valuable than raw technical expertise, especially services that must not fail, such as DNS and DHCP (but YMMV).
After
The only significant change in how roles were allocated was to consciously discuss the trade-offs associated with each of the candidates across more than just the “technical expertise” dimension. How that person will be perceived by downstream teams is also important, especially if multiple teams need to coordinate in order to deliver a service. While shaky at the start, they soon developed a degree of skill and nuance when thinking about these additional, non-technical dimensions.
I’ve also recommended that as part of the pod mission statements that they also make some brief comments about the trade-offs that they’ve made to come up with their operating model and structure. This is doubly important for teams that haven’t explicitly articulated their purpose before. The deliberate articulation of (for example) prioritising credibility with peers and service stability over raw speed of delivery makes it much clearer about why a team engages and prioritises the way that it does. It also acts as a trigger for team leaders to develop a range of leadership styles, as they’re able to recognise traits and weaknesses in themselves that little bit more easily.