Intended Audience
So you’ve bought into the SAFe brand, adopted it pretty much wholesale. You might even have had some successes after the initial adoption. But at some point, you’ve hit a plateau (or a major problem that you simply can’t get past with just SAFe’s guidance). Perhaps you need a shorter time to market than a quarterly planning cycle gives you. What do you do?
The rest of this post is structured very loosely as a set of steps. They generally make sense as a progression, but the reality is that for even remotely complex contexts, if you attempted to follow this line through just once, you’re likely to end up with more pain. There are feedback loops all over the place, and artificially trimming them into a single line is a waterfall-esque strategy for complexity management, which is suboptimal.
Step 0 – Don’t Panic!
You’re already on a transformation journey (Before SAFe -> Adopting SAFe -> Using SAFe -> ?). This is just the next step.
Step 1 – Start where you are
There’s no sense ramping up the psychological harm by saying you were wrong. Elements such as the Prime Directive of Retrospectives also echo the underlying fact that at the time, you made the best decision possible given the data you had access to. Now that you have more (or perhaps just different) data, it’s time to make the best decision possible today.
Step 2 – Take Stock
Look at what you have (in this case, SAFe) and focus on the mindset, and principles, as those generally remain valid. What will change is the practices, techniques and strategies that you use in order to sustain that mindset and deliver value continuously. For example, “Alignment” is great. SAFe’s implementation strategy for achieving alignment is generally by starting from the Portfolio level and “working down”. Other strategies include starting from the team and “working outwards”. Changing the scale of programmes of work (e.g. by picking an architectural style that facilitates this) can change the relative importance of alignment from being a pre-requisite into more of a side-effect. Disciplined Agile Delivery (DAD) has an Enterprise Aware principle that can be used to facilitate a discussion about Alignment.
Step 3 – Visualise The Implicit
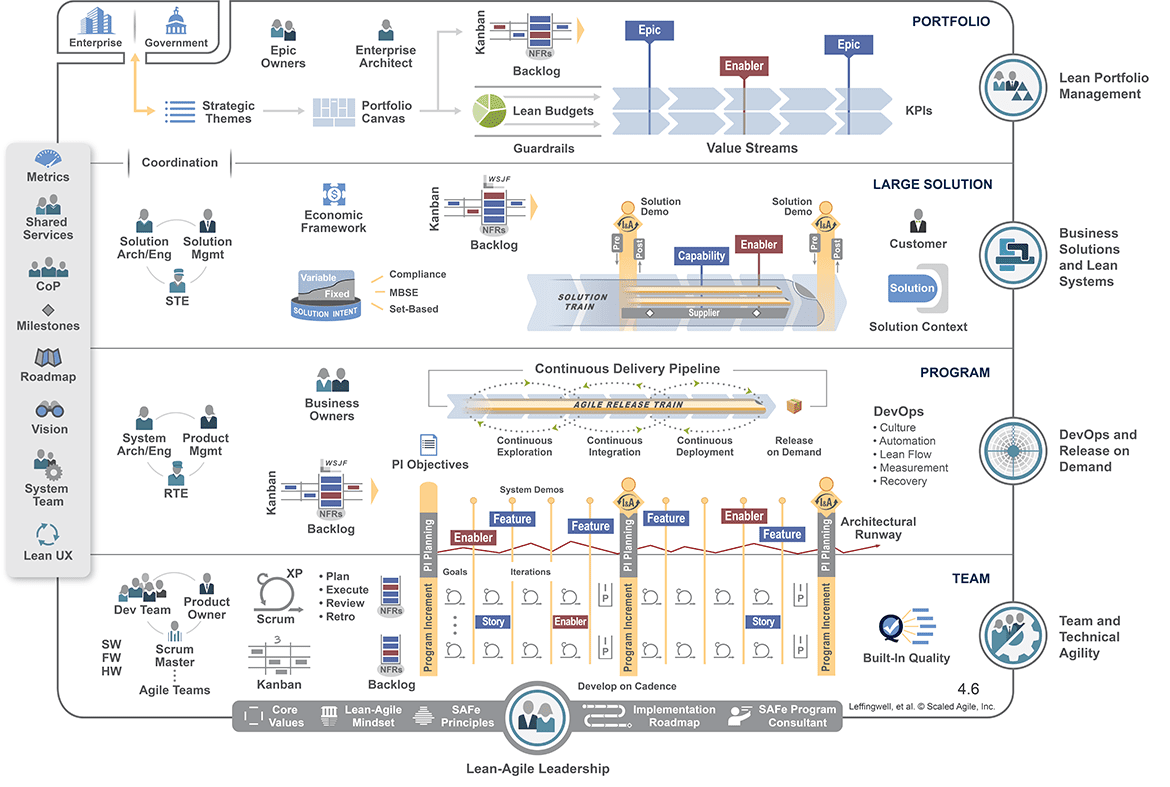
Visualise your Ways of Working. (WoW). If you’ve adopted SAFe, then the SAFe “Big Picture” is probably it, or very close to it. DAD has a Program Lifecycle, which bar some label changes is very similar. Once your WoW is visual, overlay it with DAD terminology. This is a form of gap analysis and it should help you turn implicit process knowledge into explicit knowledge. The biggest insights would come from the associated “Process Goals” for the practices you are using. That’s a big step towards understanding why a practice is used. SAFe’s guidance is very good at telling you what to do and has some coverage of why it’s worthwhile. What is lacking though, are alternative approaches for achieving the same objective. That’s where DAD can offer significant advantages.
Step 4 – Target Process Improvements
With a map of process goals, now it becomes possible to target improvements to struggling areas. The areas to target will be highly context specific, and it’s worth using some root-cause-analysis techniques (e.g. 5 Whys or Ishikawa diagrams) to find them. Using a process goal as an anchor, you are more easily able to explore alternative strategies to solve the problem you’ve got. For example, if your current processes struggle with effective delivery of complex non-functional-requirements, then something like http://disciplinedagiledelivery.com/strategies-for-verifying-non-functional-requirements/ could help.
Step 4A – Have Meaningful Conversations
An interesting side effect of making your process goals visible, is you can engage your teams and stakeholders in a more meaningful discussion about the approach to the work. This can create space for highly innovative and inventive strategies for problem solving and value delivery to emerge.
Or in other words, instead of only relying on your team to think-outside-the-box, you get to redefine-what-you-mean-by-box.
Step 5 – Rinse and Repeat – Ad Nauseum
Don’t forget one of the pillars of the (SAFe) House of Lean – Relentless Improvement. Your drive to improve shouldn’t end. One of the challenges with adopting SAFe (or in fact any other branded framework that has a relatively prescriptive nature) is the illusion that there’s an End State to reach, and once you get there, you win the game.
Looking at the Twitterverse, I’ve seen a few people talk about SAFe being potentially a good way to start getting some agility into your large scale programme delivery – mainly because can be perceived by senior-management-buyers as a Tangible Thing, which is easier to accept than a grass-roots-hearts-and-minds-campaign-led-by-developers. However, at some point, a continuously evolving organisation will evolve beyond it. That said, the subset of SAFe that’s Don Reinertson’s work on Economics and Flow will remain relevant long after the SAFe practices are abandoned for more lightweight alternatives.