a.k.a. why are some people SAFe oriented, others DAD biased, yet others LeSS enthusiasts, and not forgetting the DSDM gang, the Nexus collective…and I’m running out of terms.
I’m sure there are a whole host of reasons, but during my time observing people, and knowing a bit about their past and what they’re like, it has led me to form an interesting (to me anyway) hypothesis. It’s to do with power.
A Brief History of Power
Without digging too far too much into Taylorism or others, there are a handful of basic power models that can theoretically exist in an organisation (heavily simplified for illustrative purposes, as real life is never this “simple”).
- Power in the hierarchy, the higher up you go, the more power you have
- Power in the middle management – sometimes disparagingly called the permafrost
- Power on the edges – people on the ground in front of customers
These can manifest themselves onto a project context in a few ways (note for want of better options, I’m labelling these categories with overloaded terms)
- Power lies with the “planners” – e.g. project managers, PMO
- Power lies with the “architects” – EAs, Solution Architects
- Power lies with the “developers” – developers, testers, BAs
Human nature is such that we flock towards things that are like us. Planners are more likely to favour other planners, and work using systems where the balance of power is in their direction. The same sort of thing is true for the Architects and the Developers.
Methods
And now we get to the Methods part of this blog. I’m going to focus on agile methods, and agile scaling frameworks. And in particular, how these methods and frameworks are perceived, at least initially. That bit is key. Most of this “natural affinity” stuff is emotional in nature, and not fundamentally driven by rational thinking (hint: there’s a lot of religion in this area). As there are lots of them out there, I’ll just pick the three major ones (based entirely on how often clients talk to me about agile at scale, and nothing remotely scientific).
SAFe
The overall guidance is dominated by the navigable map. It has several terms that will be comforting and reassuring to hierarchical type organisations with traditional reporting lines and financial controls – Programme / Portfolio Management, Enterprise Architect, as well as some guidance on mixing waterfall and agile deliveries. This looks to be solidly planted in the middle of the “Planners” camp.
Based on the hypothesis, likely proponents and allies are to be found within PMO, Project Governance,Configuration Managers, hierarchical organisations with a centralised power model, and organisations that perceive themselves to be traditional with a rich history / heritage.
DAD
The first thing that strikes you when you first look at DAD is that it’s rammed to the rafters with choices. It has a risk-value lifecycle (but you can choose others), many options on how to achieve pretty much any delivery related goal that you may have – from big ticket items such as considering the future – how much architectural insight do you need, to very focussed options like the right level of modelling to use. And that’s just part of the “Identify Initial Technical Strategy” goal. This resonates well with those with an architectural bias – architecture is mostly about decision making and communication.
Likely proponents and allies are to be found in technical leadership – Architects, DBAs, and organisations with a strong technical bias.
LeSS
The navigation map for LeSS in contrast to the previous two, looks relatively uncluttered. There are large concepts identified (such as Systems Thinking, Adoption) but these are all located around the periphery of the diagram. Slap bang in the middle is the engine, and those are feature teams. This puts the Developer at the centre of the universe (as it were).
Likely proponents and allies are to be found within teams and individuals using Scrum and XP on a regular / daily basis, and organisations that “have a small company vibe”, which may be startups on a growth spurt, or organisations in a highly fluid environment with significant localised decision making.
The Goldilocks Solution
As the heading suggests, I think the right mix for any given organisation is somewhere in the middle. Power isn’t solely contained within a single area (though granted, in many cases, the vast majority of the power is indeed concentrated that way), and any scaled agile adoption strategy will need to understand and accommodate that to increase the chances of tangible benefits being felt by the organisation.
Feedback
As this is just a hypothesis I’ve got, I’d love to hear what you think, whether you’ve observed things that support this theory, disprove it entirely, or somewhere in between.







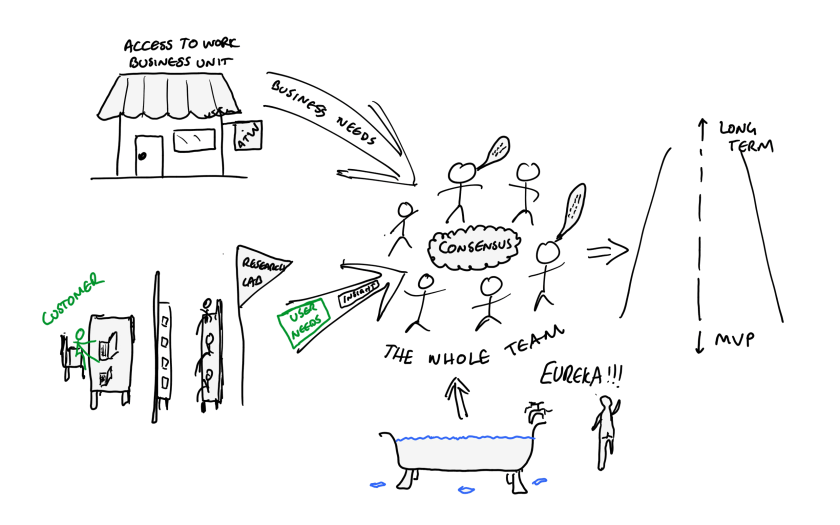
 Instead of conducting the experiment with theoretical users and pretend demands like before, we’d employ A/B or multivariate testing, build alternative flows through our system and just measure what our actual customers did. To measure demand for a new feature, we’d just put a button on the screen and count the number of times it was clicked (users would be given a “we’re assessing the demand for this feature, your interest has been registered, in the meantime do this” message). The proven hypotheses were demonstrably proven as the outcomes were better (as opposed to before when they were still technically just theoretical). The cost was that disproved hypotheses needed additional work to remove the code from the live system. We thought it was a cost worth paying.
Instead of conducting the experiment with theoretical users and pretend demands like before, we’d employ A/B or multivariate testing, build alternative flows through our system and just measure what our actual customers did. To measure demand for a new feature, we’d just put a button on the screen and count the number of times it was clicked (users would be given a “we’re assessing the demand for this feature, your interest has been registered, in the meantime do this” message). The proven hypotheses were demonstrably proven as the outcomes were better (as opposed to before when they were still technically just theoretical). The cost was that disproved hypotheses needed additional work to remove the code from the live system. We thought it was a cost worth paying.